Going The Distance: How Travel Behavior Influences Climate-Related Policy Preferences in Washington State
Author
Affiliation
Tiernan Martin
Futurewise
Abstract
This research investigates how household travel behavior in Washington State influences voter support for climate-related fiscal policies, such as carbon taxes and cap-and-trade systems, using a harmonized census tract-scale dataset and multiple statistical models.
Keywords
Carbon Tax, Travel Behavior, Vehicle Miles Traveled
In [1]:
library(here)
here() starts at C:/Users/tiern/Documents/R/2024-wa-climate-voting
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
To enable caching of data, set `options(tigris_use_cache = TRUE)`
in your R script or .Rprofile.
Attaching package: 'tigris'
The following object is masked from 'package:tidycensus':
fips_codes
Attaching package: 'janitor'
The following objects are masked from 'package:stats':
chisq.test, fisher.test
Loading required package: spData
To access larger datasets in this package, install the spDataLarge
package with: `install.packages('spDataLarge',
repos='https://nowosad.github.io/drat/', type='source')`
Loading required package: Matrix
Attaching package: 'Matrix'
The following objects are masked from 'package:tidyr':
expand, pack, unpack
Attaching package: 'spatialreg'
The following objects are masked from 'package:spdep':
get.ClusterOption, get.coresOption, get.mcOption,
get.VerboseOption, get.ZeroPolicyOption, set.ClusterOption,
set.coresOption, set.mcOption, set.VerboseOption,
set.ZeroPolicyOption
This research explores the relationship between household travel behavior and voter preferences for climate-related fiscal policy in Washington State. We examine how variations in travel patterns might influence public support for specific climate change change-related fiscal policies such as carbon taxes or “cap and trade” emission trading systems. The analysis builds a harmonized, census tract-scale data set and uses several statistical models to explore the relationship between these variables.
2 Data and Methods
2.1 Data Opertionalization
Travel Behavior: Represented by average daily vehicle miles traveled (VMT) per household, sourced from the US Department of Transportation’s Local Characteristics for Households dataset. This metric reflects household mobility patterns.
Voter Preferences for Climate-Related Taxes: Quantified through the results of two ballot initiatives: I-732 in 2016, which proposed a carbon fee aimed at reducing greenhouse gas emissions; and I-1631 in 2018, which proposed a similar fee that would have funded a variety of climate justice programs. The results of these ballot initiatives serve as a direct measure of voter support for climate-related taxation.
Political Partisanship: Operationalized using the results of 2016 presidential election and 2018 US Senate election, indicating the political values of voters, which may influence their support for environment- and/or taxation-related policy.
The study data are reported in two non-coterminous geographies: census tracts and voting precincts. Our method uses population-weighted areal interpolation to estimate voting precinct results at the census tract scale.1
The study data is divided in two subsets, one for the 2016 election and another for the 2018 election; the average daily VMT results are only available for 2016, so that data is joined to both election data subsets to construct the study database.
2.2 Model Descriptions
Our method fits a series of linear regression models of increasing complexity in order to understand the relationship between our explanatory and response variables. Each model type is fit to the two subsets of the study database.
2.2.1 Univariate Linear Models
The first model type is a univariate Ordinary Least Squares regression that assumes a direct relationship between voter support for the climate-related tax and household travel behavior. We fit the model to This model is articulated through the following linear equation:
\[
y_i = \beta_0 + \beta_1x_{1i} + \epsilon_i
\]
In this equation:
\(y_i\) represents the response variable, specifically the share of ‘No’ votes on I-732 or I-1631.
\(\beta_0\) is the y-axis intercept, indicating the baseline level of opposition to the initiative when average daily VMT per household is zero.
\(\beta_1x_{1i}\) is the coefficient for the explanatory variable, average daily VMT per household, which quantifies the change in the proportion of ‘No’ votes as VMT varies.
\(\epsilon_i\) denotes the random error term, accounting for the variation in ‘No’ votes not explained by travel behavior.
Here, \(y_i\) represents the response variable (share of ‘No’ votes on I-732 or I-1631), \(\beta_0\) is the model’s y-axis intercept, \(\beta_1x_{1i}\) is the coefficient of the explanatory variable (average daily VMT per household), and \(\epsilon_i\) represents the random error term.
This model establishes a baseline for identifying potential correlations between travel behavior and voter preferences regarding climate-related taxes, without considering any other confounding factors. It provides a straightforward way to assess the primary effect of travel on voting behavior before introducing more complexity into the analysis.
2.2.2 Multivariate Linear Model
Expanding upon the univariate linear model, the multivariate linear model incorporates an additional explanatory variable: political partisanship. This model is specified through the following equation:
In this equation, \(\beta_2x_{2i}\) is the coefficient of the additional explanatory variable (share of votes for the Republican presidential candidate in 2016 or the Republican US Senate candidate in 2018).
This model evaluates how both travel behavior and political orientation together affect support for climate-related taxes.
2.2.3 Spatial Lag Model
The Spatial Lag Model refines the multivariate Extended Linear Model by including a spatial lag variable that accounts for “spillover effect” (i.e., spatial autocorrelation of model residuals) of the multivariate linear model’s dependent variable.
\(\rho\) is the spatial-autoregressive coefficient
\(w\) is a spatial weights matrix
Each model progressively incorporates more complexity to address different hypotheses about the influences on voter preferences regarding climate policy in Washington State. This approach allows for a nuanced analysis, distinguishing direct effects from those mediated by political identity or spatial proximity.
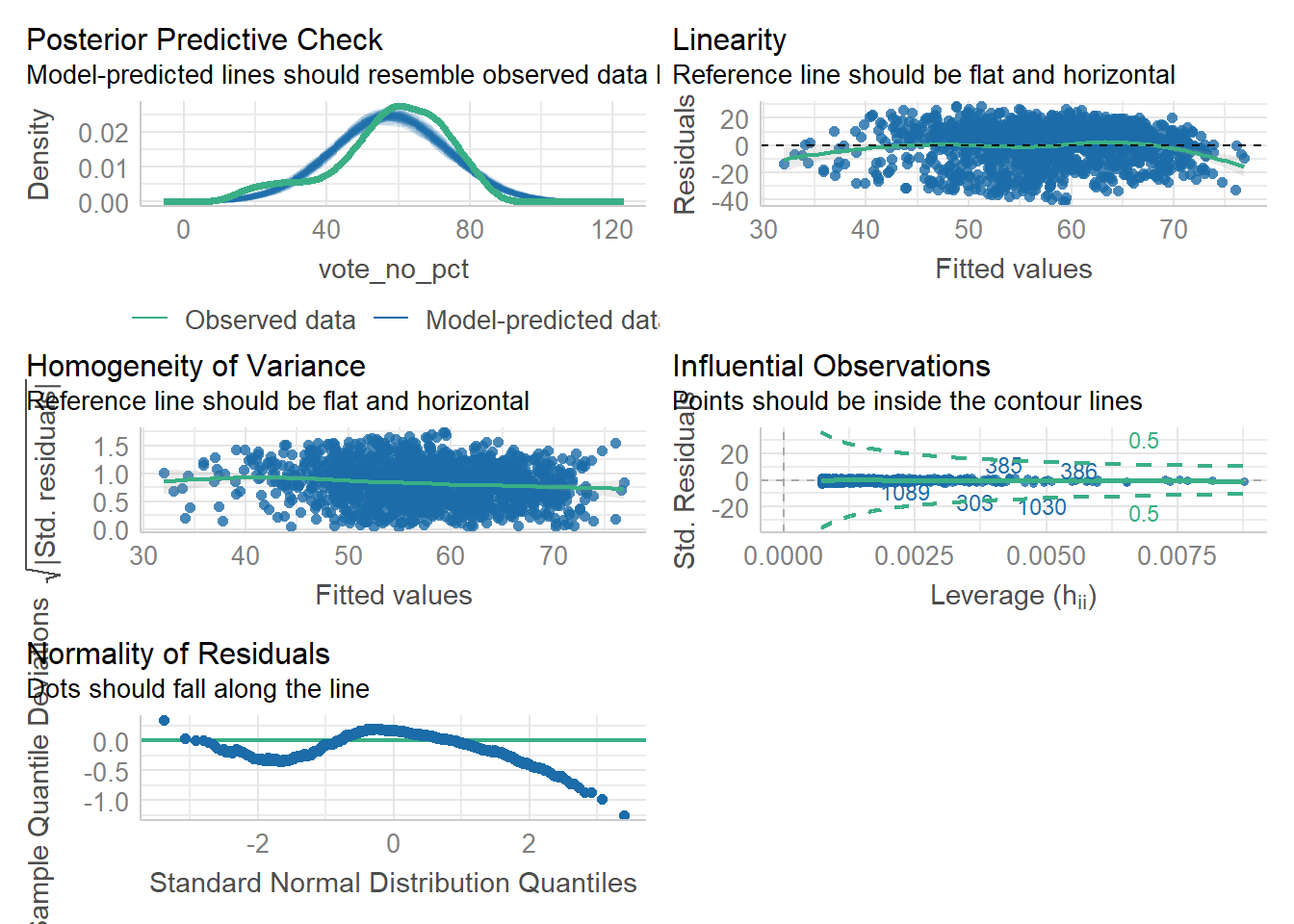
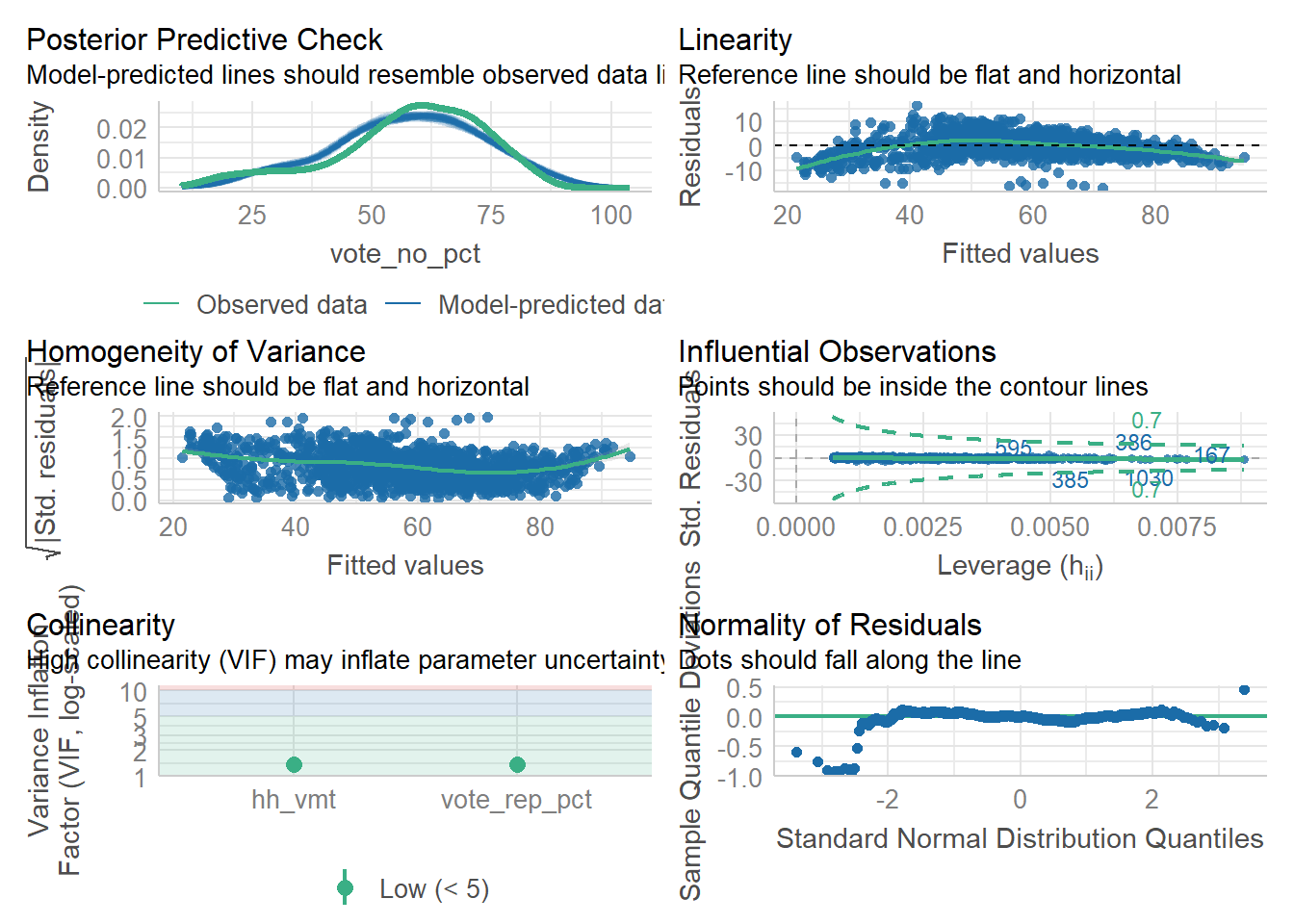
3 Results
3.1 Data
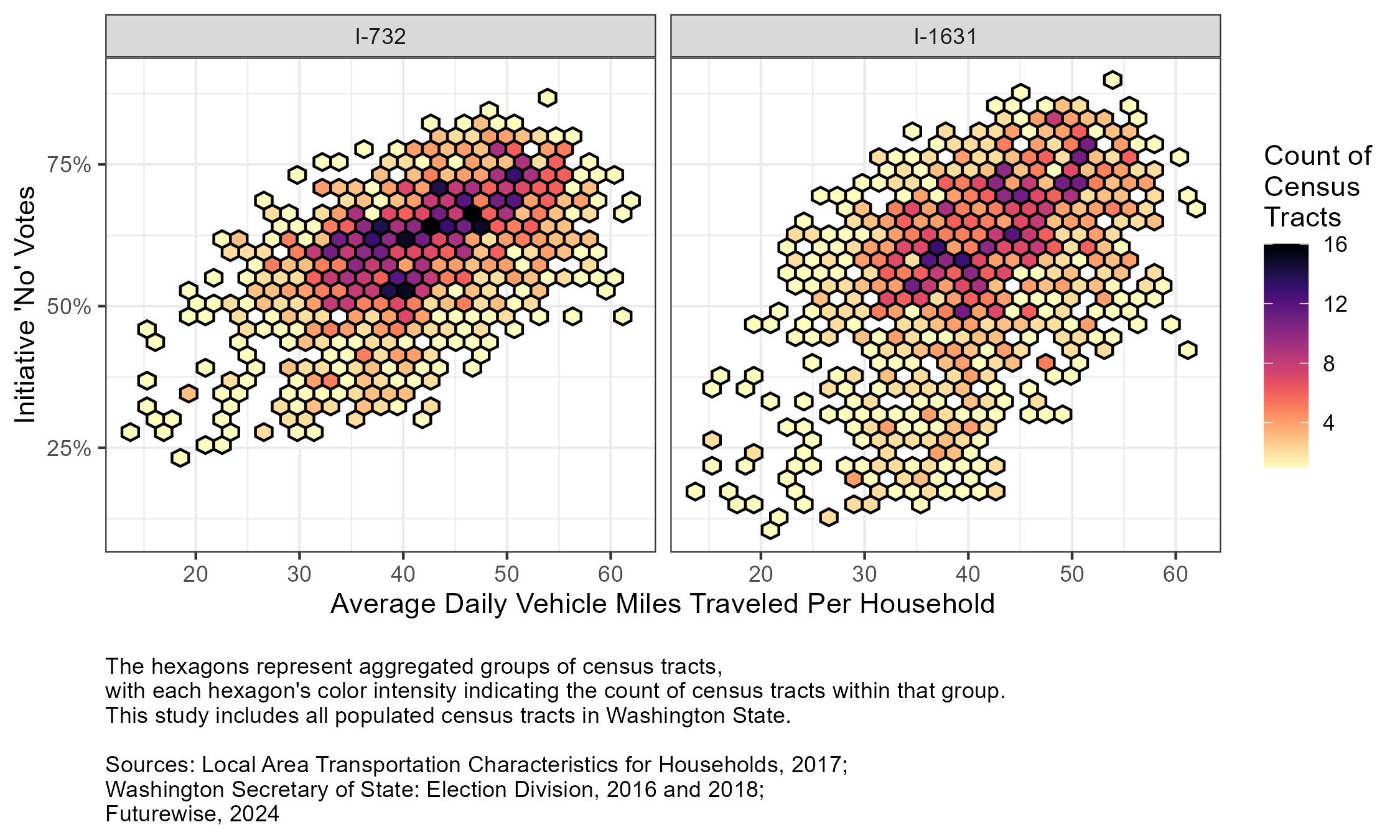
Exploratory data analysis of the study database suggests that a positive relationship may exist between the response variable (climate initiative voting results) and the primary explanatory variable (average daily VMT).
Hexagonal bin scatterplot of the study’s primary response and explanatory variables
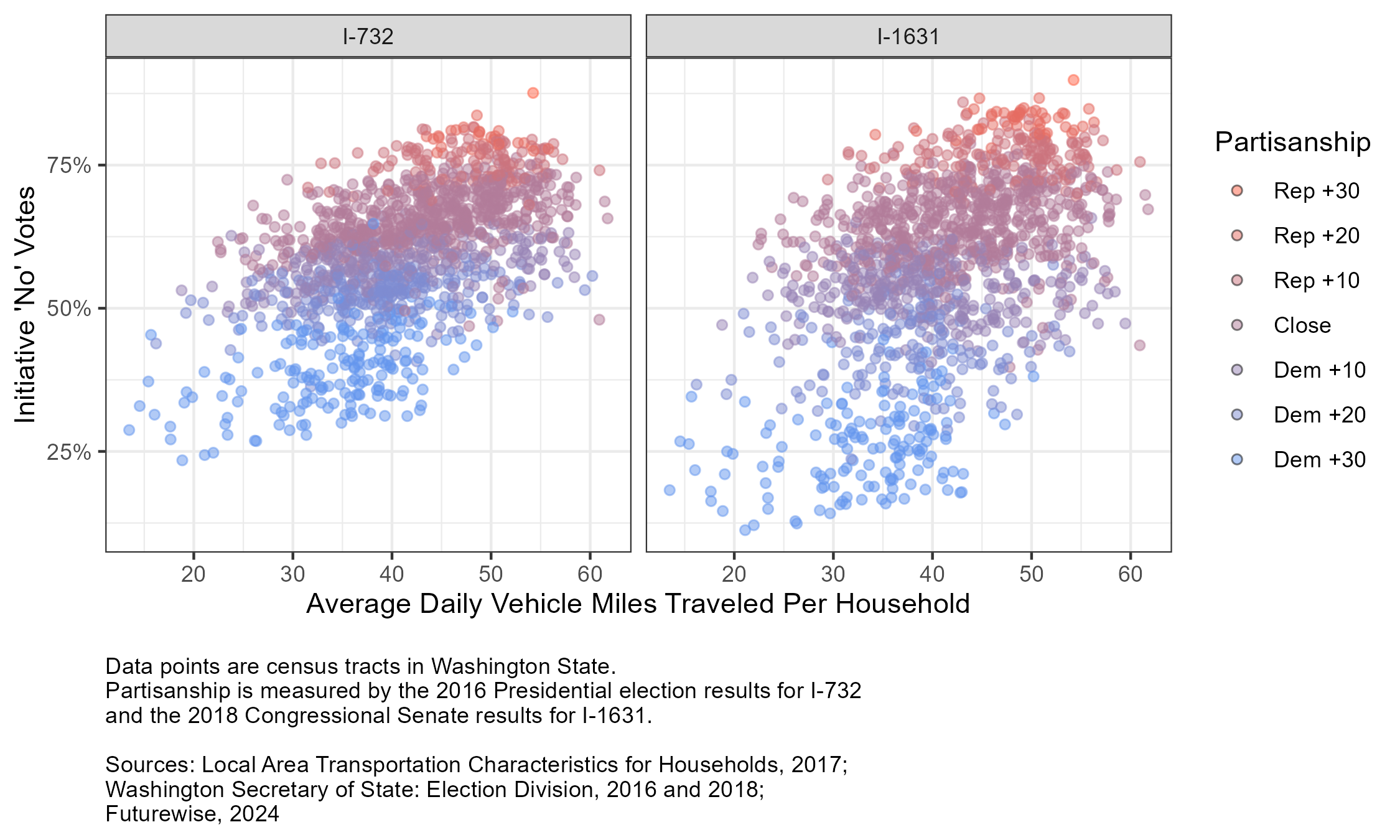
Introducing political partisanship as an intervening variable in the data visualization suggests that it will likely have a significant impact on the model coefficients.
Scatterplot showing the relationship between climate-initiative voting, travel behavior, and political partisanship.
3.2 Models
The results of the three model types fit to each data subset are summarized in the table below:
The univariate model results suggest a straightforward relationship: opposition to climate-related taxes is positively correlated with the average vehicle miles traveled. For I-732, for each additional mile traveled, we expect opposition to increase by 0.74%. For I-1631, that increase is 0.93%. In both cases, the results are statistically significant.
However, introducing political partisanship in the multivariate model significantly changes the results. For I-732, the coefficient drops to a 0.13% increase in opposition per additional mile traveled, and the coefficient remains statistically significant. For I-1631, the coefficient reduces to near zero and becomes non-significant.
Accounting for spatial autocorrelation in the data yields similar results: the explanatory power of household VMT significantly reduces the effect of political partisanship on the response variable. This result suggests that spatial proximity plays a meaningful role in the underlying relationships explored in the study.
Moran I test under randomisation
data: residuals(model_i732_lm_multivariate)
weights: model_i732_spatial_weights
n reduced by no-neighbour observations
Moran I statistic standard deviate = 29.925, p-value < 2.2e-16
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.4875875930 -0.0007007708 0.0002662552
5.3.4 Spatially Lagged Regression
Spatial lag model parameters:
In [12]:
summary(model_i732_spatial_lag, Nagelkerke =TRUE)
Call:lagsarlm(formula = model_lm_multivariate, data = model_data,
listw = model_spatial_weights, zero.policy = TRUE)
Residuals:
Min 1Q Median 3Q Max
-18.95558 -1.63454 0.16726 1.80358 18.90741
Type: lag
Regions with no neighbours included:
523 1102 1253
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 19.431901 0.683653 28.424 < 2.2e-16
hh_vmt 0.150062 0.010119 14.829 < 2.2e-16
vote_rep_pct 0.455436 0.010999 41.406 < 2.2e-16
Rho: 0.27083, LR test value: 273.23, p-value: < 2.22e-16
Asymptotic standard error: 0.016385
z-value: 16.529, p-value: < 2.22e-16
Wald statistic: 273.21, p-value: < 2.22e-16
Log likelihood: -3506.789 for lag model
ML residual variance (sigma squared): 7.7613, (sigma: 2.7859)
Nagelkerke pseudo-R-squared: 0.93803
Number of observations: 1431
Number of parameters estimated: 5
AIC: 7023.6, (AIC for lm: 7294.8)
LM test for residual autocorrelation
test value: 404.9, p-value: < 2.22e-16
Moran I test under randomisation
data: residuals(model_i1631_lm_multivariate)
weights: model_i1631_spatial_weights
n reduced by no-neighbour observations
Moran I statistic standard deviate = 41.796, p-value < 2.2e-16
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.6885373931 -0.0007112376 0.0002719450
Call:lagsarlm(formula = model_lm_multivariate, data = model_data,
listw = model_spatial_weights, zero.policy = TRUE)
Residuals:
Min 1Q Median 3Q Max
-20.32096 -2.04723 0.15611 2.08935 19.30558
Type: lag
Regions with no neighbours included:
514 1088 1235
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 9.8173977 0.6123369 16.0327 <2e-16
hh_vmt 0.0044388 0.0133214 0.3332 0.739
vote_rep_pct 0.6024454 0.0157045 38.3614 <2e-16
Rho: 0.38397, LR test value: 543.16, p-value: < 2.22e-16
Asymptotic standard error: 0.01607
z-value: 23.894, p-value: < 2.22e-16
Wald statistic: 570.91, p-value: < 2.22e-16
Log likelihood: -3792.061 for lag model
ML residual variance (sigma squared): 12.319, (sigma: 3.5099)
Nagelkerke pseudo-R-squared: 0.94846
Number of observations: 1410
Number of parameters estimated: 5
AIC: 7594.1, (AIC for lm: 8135.3)
LM test for residual autocorrelation
test value: 711.5, p-value: < 2.22e-16
Hexagonal bin scatterplot of the study’s primary response and explanatory variablesScatterplot showing the relationship between climate-initiative voting, travel behavior, and political partisanship.Figure 4: Figure 5: Figure 9: Figure 10:
The study uses the interpolate_pw() function from the tidycensus package to estimate voting precinct results at the census tract scale.↩︎